

HQ3DAvatar: High Quality Implicit 3D Head Avatar
1Max Planck Institute for Informatics, Saarland Informatics Campus
2Nanyang Technological University, Singapore
3Imperial College London
4Flawless AI
ACM Transactions on Graphics
(ACM TOG 2024)
(ACM TOG 2024)
Abstract
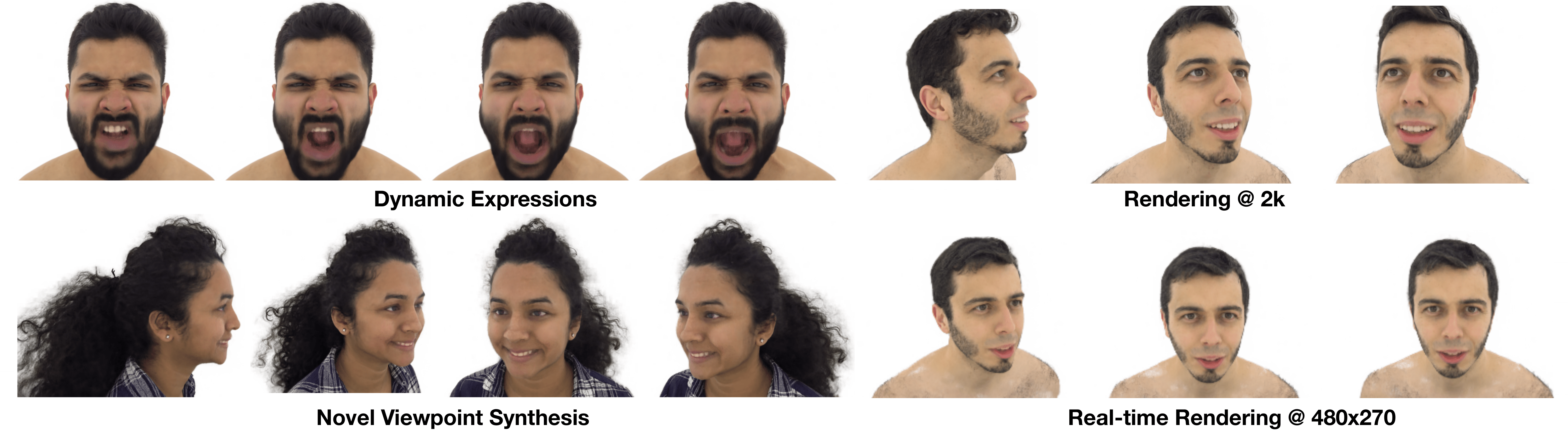
Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A comm- on approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms the related approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research.
Downloads

Citation
Acknowledgments
This work was supported by the ERC Consolidator Grant 4DReply (770784).
Contact
For questions, clarifications, please get in touch with:Kartik Teotia
kteotia@mpi-inf.mpg.de