

†Equal advising and corresponding authors.
Existing automatic approaches for 3D virtual character motion synthesis supporting scene interactions do not generalise well to new objects outside training distributions, even when trained on extensive motion capture datasets with diverse objects and annotated interactions. This paper addresses this limitation and shows that robustness and generalisation to novel scene objects in 3D object-aware character synthesis can be achieved by training a motion model with as few as one reference object. We leverage an implicit feature representation trained on object-only datasets, which encodes an SE(3)-equivariant descriptor field around the object. Given an unseen object and a reference pose-object pair, we optimise for the object-aware pose that is closest in the feature space to the reference pose. Finally, we use l-NSM, i.e., our motion generation model that is trained to seamlessly transition from locomotion to object interaction with the proposed bidirectional pose blending scheme. Through comprehensive numerical comparisons to state-of-the-art methods and in a user study, we demonstrate substantial improvements in 3D virtual character motion and interaction quality and robustness to scenarios with unseen objects.
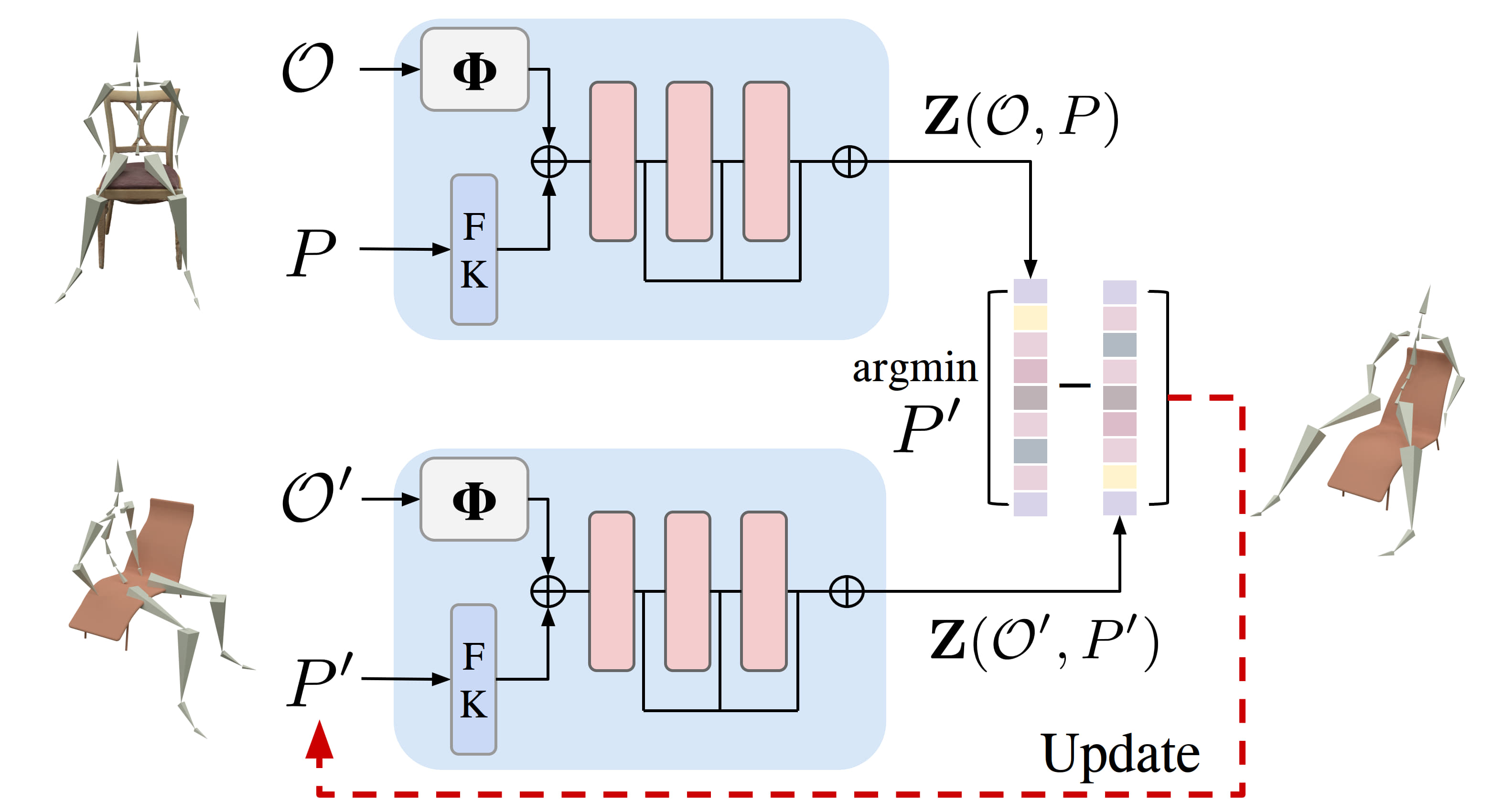
This work was carried out as part of a dissertation at Saarland University. This project was also supported by Saarbrucken Research Center ¨ for Visual Computing, Interaction and AI. Christian Theobalt was supported by ERC Consolidator Grant 4DReply (770784). We thank Janis Sprenger for helpful discussions on experiment design and visualisation.
@article{zhang2024roam,
title = {ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors},
author = {Zhang, Wanyue and Dabral, Rishabh and Leimk{\"u}hler, Thomas and Golyanik, Vladislav and Habermann, Marc and Theobalt, Christian},
year = {2024},
journal={International Conference on 3D Vision (3DV)}
}