Graphics, Vision & Video
Efficient ConvNet-based Marker-less Motion Capture
in General Scenes with a Low Number of Cameras
| Ahmed Elhayek 1 | Edilson De Aguiar 1 | Arjun Jain 2 | Jonathan Tompson 2 | Leonid Pishchulin 1 |
| Micha Andriluka 3 | Christoph Bregler 2 | Bernt Schiele 1 | Christian Theobalt 1 |
| 1 MPI for Informatics | 2 New York University | 3 Stanford University |
| Abstract | Videos | Bibtex |
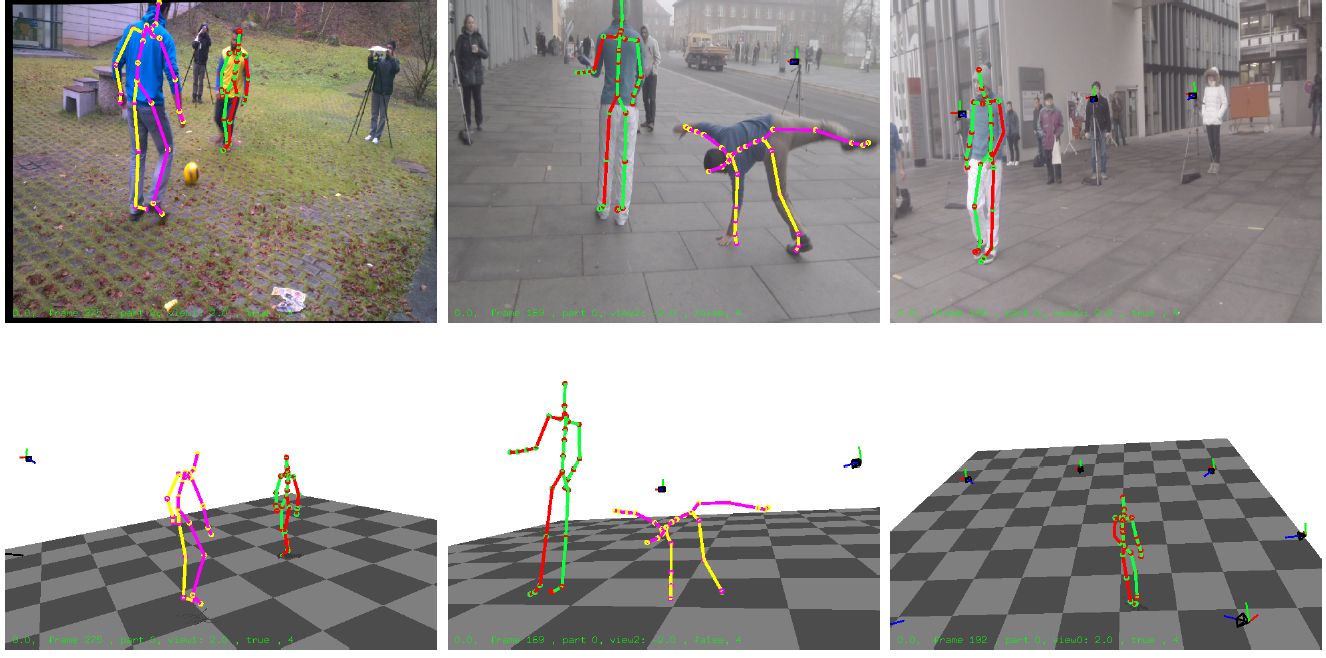
We present a novel method for accurate marker-less capture of articulated skeleton motion of several subjects in general scenes, indoors and outdoors, even from input filmed with as few as two cameras. Our approach unites a discriminative image-based joint detection method with a model-based generative motion tracking algorithm through a combined pose optimization energy. The discriminative part-based pose detection method, implemented using Convolutional Networks (ConvNet), estimates unary potentials for each joint of a kinematic skeleton model. These unary potentials are used to probabilistically extract pose constraints for tracking by using weighted sampling from a pose posterior guided by the model. In the final energy, these constraints are combined with an appearance-based model-to-image similarity term. Poses can be computed very efficiently using iterative local optimization, as ConvNet detection is fast, and our formulation yields a combined pose estimation energy with analytic derivatives. In combination, this enables to track full articulated joint angles at state-of-the-art accuracy and temporal stability with a very low number of cameras.
 |
 |
 |
 |
| Paper pdf (9.0M) |
Video avi (65.1M) |
supplementary material pdf (1.4M) |
Presentation not yet available |
| Supplementary video to the paper |
@inproceedings {EEJTP15,
author = {A. Elhayek and E. Aguiar and A. Jain and J. Tompson and L. Pishchulin and M. Andriluka and C. Bregler and B. Schiele and C. Theobalt},
title = {Efficient ConvNet-based Marker-less Motion Capture in General Scenes with a Low Number of Cameras},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
month = {June},
}
|