Pipeline
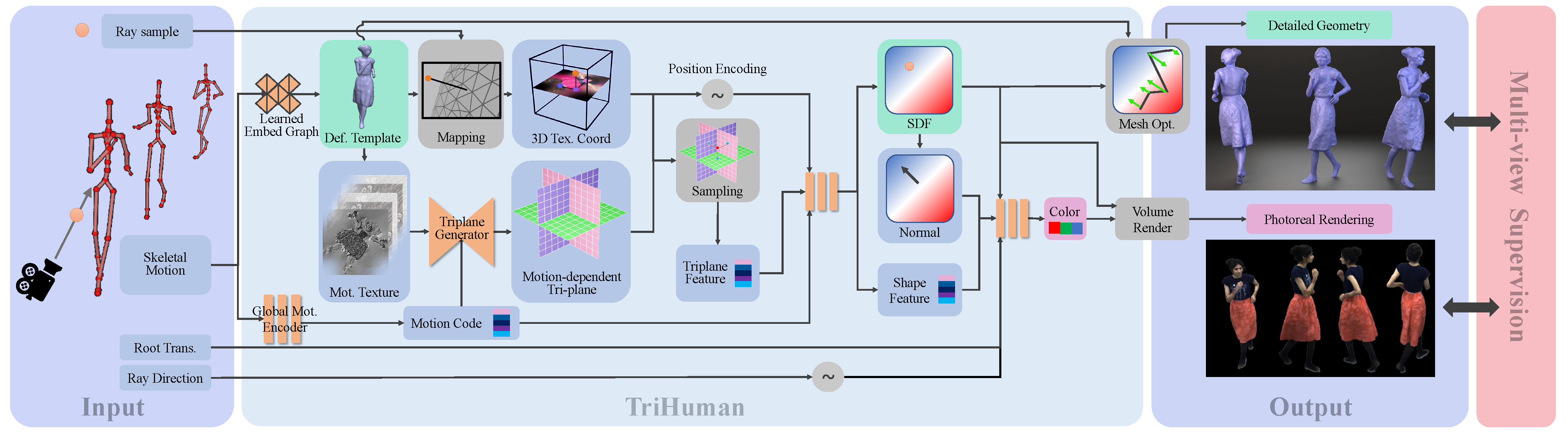
Figure 2.: Given a skeletal motion and virtual camera view as input, our method generates highly realistic renderings of the human under the specified pose and view.
To this end, first a rough motion-dependent and deforming human mesh is regressed.
From the deformed mesh, we extract several motion features in texture space, which are then passed through a 3D-aware convolutional architecture to generate a motion-conditioned feature tri-plane.
Ray samples in global space can be mapped into a 3D texture cube, which can be then used to sample a feature from the tri-plane.
This feature is then passed to a small MLP predicting color and density.
Finally, volume rendering and our proposed mesh optimization can generate the geometry and images.
Our method is solely supervised on multi-view imagery.







