

Our ConvoFusion approach generates body and hand gestures in monadic and dyadic settings, while also offering advanced control over textual and auditory modalities in speech. Lastly, we introduce the DnD Group Gesture dataset, showcasing rich interactions with co-speech gestures between five participants.
Gestures play a key role in human communication. Recent methods for co-speech gesture generation, while managing to generate beat-aligned motions, struggle generating gestures that are semantically aligned with the utterance. Compared to beat gestures that align naturally to the audio signal, semantically coherent gestures require modeling the complex interactions between the language and human motion, and can be controlled by focusing on certain words. Therefore, we present ConvoFusion, a diffusion-based approach for multi-modal gesture synthesis, which can not only generate gestures based on multi-modal speech inputs, but can also facilitate controllability in gesture synthesis. Our method proposes two guidance objectives that allow the users to modulate the impact of different conditioning modalities (e.g. audio vs text) as well as to choose certain words to be emphasized during gesturing. Our method is versatile in that it can be trained either for generating monologue gestures or even the conversational gestures. To further advance the research on multi-party interactive gestures, the DnD Group Gesture dataset is released, which contains 6 hours of gesture data showing 5 people interacting with one another. We compare our method with several recent works and demonstrate effectiveness of our method on a variety of tasks.
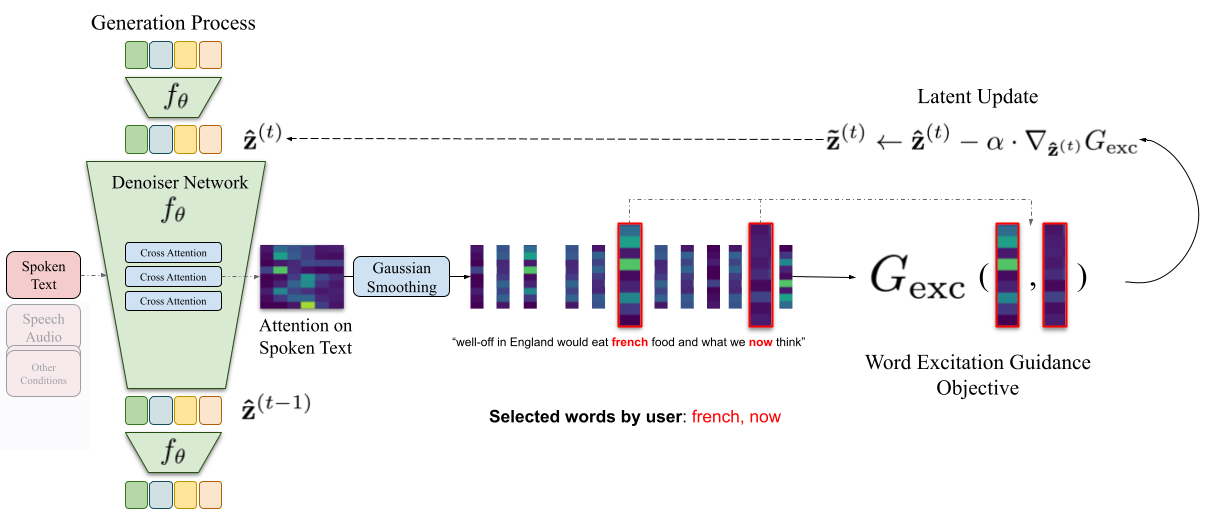
Our Word Excitation Guidance (WEG) mechanism allows us to finely control the gesture generation based on a user-defined set of words during the generation process.
We can also utilize state-of-the-art human rendering techniques like ASH to animate body and hands for co-speech gesture synthesis.
@InProceedings{mughal2024convofusion,
title = {ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis},
author = {Muhammad Hamza Mughal and Rishabh Dabral and Ikhsanul Habibie and Lucia Donatelli and Marc Habermann and Christian Theobalt},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
This work was supported by the ERC Consolidator Grant 4DReply (770784). We also thank Andrea Boscolo Camiletto & Heming Zhu for help with visualizations and Christopher Hyek for designing the game for the dataset.
For questions, clarifications, please get in touch with:
Muhammad Hamza Mughal (mmughal-(at)-mpi-inf.mpg.de)