NeuS2: Fast Learning of Neural Implicit Surfaces
for Multi-view Reconstruction


Abstract
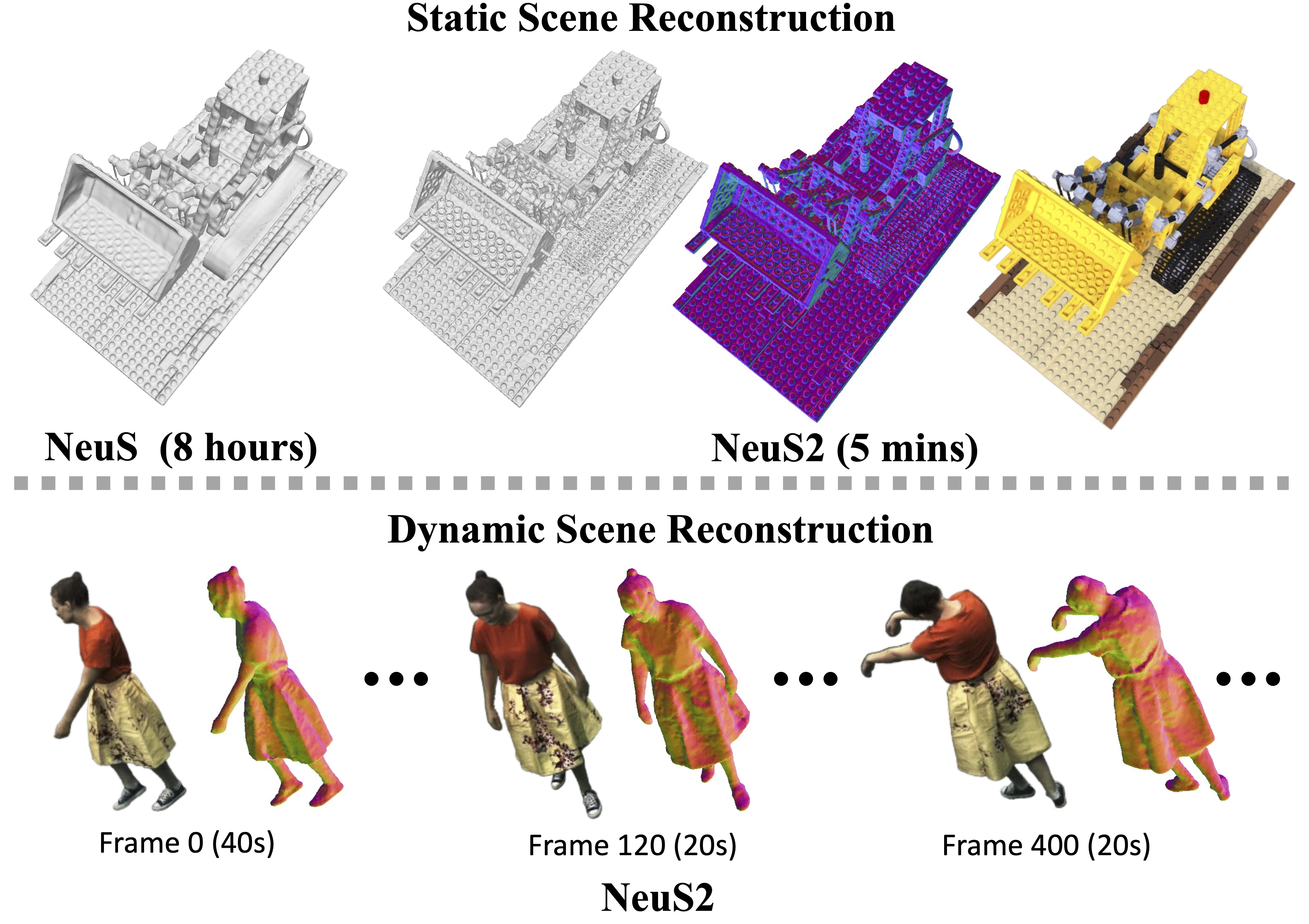
Recent methods for neural surface representation and rendering, for example NeuS, have demonstrated remarkably high-quality reconstruction of static scenes. However, the training of NeuS takes an extremely long time (8~hours), which makes it almost impossible to apply them to dynamic scenes with thousands of frames. We propose a fast neural surface reconstruction approach, called NeuS2, which achieves two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality. To accelerate the training process, we integrate multi-resolution hash encodings into a neural surface representation and implement our whole algorithm in CUDA. We also present a lightweight calculation of second-order derivatives tailored to our networks (i.e., ReLU-based MLPs), which achieves a factor two speed up. To further stabilize training, a progressive learning strategy is proposed to optimize multi-resolution hash encodings from coarse to fine. In addition, we extend our method for reconstructing dynamic scenes with an incremental training strategy. Our experiments on various datasets demonstrate that NeuS2 significantly outperforms the state-of-the-arts in both surface reconstruction accuracy and training speed.
Full Video
Introduction
We propose NeuS2, a new method for fast training of highly-detailed neural implicit surfaces from multi-view 2D images, for both static and dynamic scenes.
NeuS2 can achieve two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality.
Interactive Demo
Method
(a) Static Scene Reconstruction: Given a 3D point $x$, we locate its corresponding voxels in a multi-resolution grid and for each voxel compute the interpolation of the feature vectors of eight vertexes, stored in a hash table. Based on the input of point x and hash-encoded features, our SDF network outputs the SDF value and geometry features, which are combined with viewing direction and further fed into our RGB network to generate the RGB value. Using efficient ray-marching strategy and SDF-based volumetric rendering approach, we then compute the pixel color to render image. Notably, during backward propagation the second-order derivates are efficiently computed using our CUDA implementation.
(b) Dynamic Scene Reconstruction: Given a sequence of multi-view images, we first construct the first frame following our static reconstruction method. For every subsequent frame, we predict its global transformation with respect to the previous frame and accumulate the transformation to convert it into the canonical space (i.e. the first frame). Then, we fine-tune the parameters of NeuS2 for incremental training to generate the rendered results.
Results
Compared to NeuS and Instant-NGP, our method achieves high-quality geometry and appearance reconstruction with fine-grained details for static scene.
For the dynamic scene reconstruction, NeuS2 shows significantly improved novel view synthesis and geometry reconstruction results compared to D-NeRF. Notably, NeuS2 only uses 40 seconds to train the first frame and 20 seconds for each subsequent frame; On the contrary, D-NeRF needs an extremely long time to train such a sequence, about 20 hours.
For a long real scene sequence with 500 frames consisting of challenging movements, D-NeRF struggles to reconstruct it, and shows blurry rendering results and inaccurate geometry reconstruction, even though it is trained for about 50 hours. In contrast, NeuS2 produces photo-realistic renderings and detailed geometry, with only 20 seconds of training time per frame.
Here, we show a long real scene result containing 2000 frames. NeuS2 can handle long sequence reconstruction without compromising quality.
Citation
@inproceedings{neus2,
title={NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction},
author={Wang, Yiming and Han, Qin and Habermann, Marc and Daniilidis, Kostas and Theobalt, Christian and Liu, Lingjie},
year={2023},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}
}
Acknowledgments
This work was funded by the ERC Consolidator Grant 4DRepLy (770784) and Lise Meitner Postdoctoral Fellowship.
Contact
For any questions, please get in touch with:
Yiming Wang
wym12416@pku.edu.cn
Lingjie Liu
lingjie.liu@seas.upenn.edu