Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control


Abstract
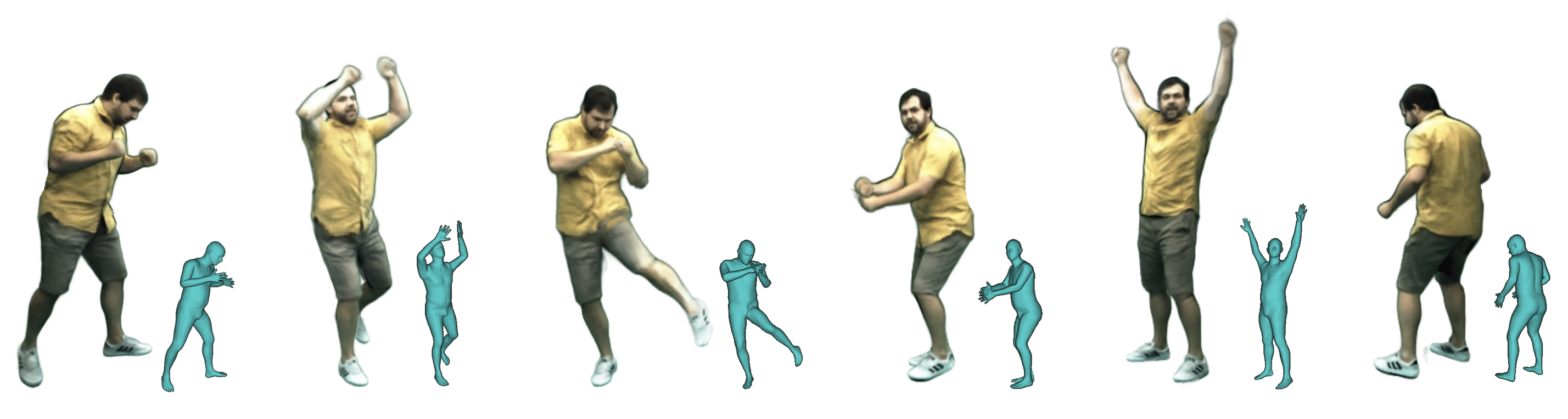
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
Full Video
Introduction
We present Neural Actor, a new method for free-view synthesis of human actors which allows arbitrary pose control. Given a sequence of driving poses as well as a virtual camera as input, our method can synthesize realistic animations of the actor with pose- and view-dependent dynamic appearance, sharp features and high-fidelity winkle patterns. We can freely change the viewpoint for rendering.
Neural Actor generalizes well to unseen poses which starkly differ from the ones in the training. Here, we show a challenging dancing performance from the AIST dataset, which was not seen during training. Note that our method also generalizes well to novel views.
Since our method only requires a skeletal pose, we can apply the same pose to different people allowing effects like synchronous crowd dancing.
We can also control the body shape of the synthesized human actors.
Method
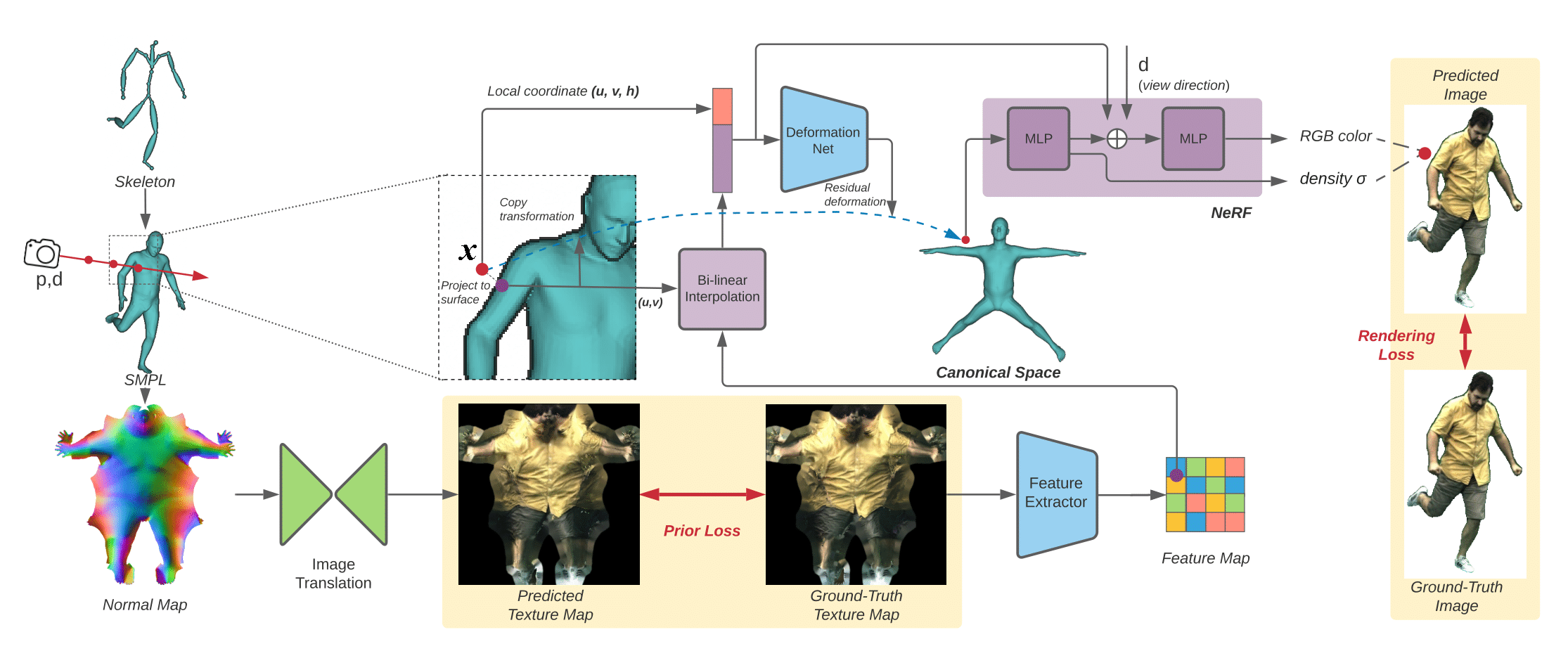
Given a pose, we synthesize images by sampling points along camera rays near the posed SMPL mesh. For each sampled point $x$, we assign to it the skinning weights of its nearest surface point and predict a residual deformation to transform $x$ to the canonical space. We then learn the radiance field in the canonical pose space to predict the color and density for $x$ using multi-view 2D supervision. The pose-dependent residual deformation and color are predicted from the local coordinate of $x$ along with the latent variables extracted from a 2D texture map of the nearest surface point of $x$. At training time, we use the ground truth texture map generated from multi-view training images to extract latent variables. At test time, the texture map is predicted from the normal map, which is extracted from the posed SMPL mesh via an image translation network, which is trained separately with the ground truth texture map as supervision.
More Reenactment Results
Citation
@article{liu2021neural,
title={Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control},
author={Lingjie Liu and Marc Habermann and Viktor Rudnev and Kripasindhu Sarkar and Jiatao Gu and Christian Theobalt},
year={2021},
journal = {ACM Trans. Graph.(ACM SIGGRAPH Asia)}
}